 |
1.10.0
User Documentation for MADlib
|


|
|
1.10.0
User Documentation for MADlib
|
|
Latent Dirichlet Allocation (LDA) is an interesting generative probabilistic model for natural texts and has received a lot of attention in recent years. The model is quite versatile, having found uses in problems like automated topic discovery, collaborative filtering, and document classification.
The LDA model posits that each document is associated with a mixture of various topics (e.g. a document is related to Topic 1 with probability 0.7, and Topic 2 with probability 0.3), and that each word in the document is attributable to one of the document's topics. There is a (symmetric) Dirichlet prior with parameter 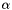 on each document's topic mixture. In addition, there is another (symmetric) Dirichlet prior with parameter
on each document's topic mixture. In addition, there is another (symmetric) Dirichlet prior with parameter 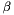 on the distribution of words for each topic.
on the distribution of words for each topic.
The following generative process then defines a distribution over a corpus of documents.
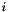 , a per-topic word distribution
, a per-topic word distribution 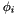 from the Dirichlet(
from the Dirichlet( 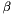 ) prior.
) prior.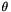 for the document from the Dirichlet(
for the document from the Dirichlet( 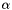 ) distribution.
) distribution.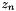 from the multinomial topic distribution .
from the multinomial topic distribution .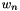 from the multinomial word distribution
from the multinomial word distribution 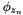 associated with topic .
associated with topic .In practice, only the words in each document are observable. The topic mixture of each document and the topic for each word in each document are latent unobservable variables that need to be inferred from the observables, and this is the problem people refer to when they talk about the inference problem for LDA. Exact inference is intractable, but several approximate inference algorithms for LDA have been developed. The simple and effective Gibbs sampling algorithm described in Griffiths and Steyvers [2] appears to be the current algorithm of choice.
This implementation provides a parallel and scalable in-database solution for LDA based on Gibbs sampling. Different with the implementations based on MPI or Hadoop Map/Reduce, this implementation builds upon the shared-nothing MPP databases and enables high-performance in-database analytics.
The vocabulary, or dictionary, indexes all the words found in the corpus and has the following format:
{TABLE|VIEW} vocab_table (
wordid INTEGER,
word TEXT
) where wordid refers the word ID (the index of a word in the vocabulary) and word is the actual word.
The training (i.e. topic inference) can be done with the following function:
SELECT lda_train(
'data_table',
'model_table',
'output_data_table',
voc_size,
topic_num,
iter_num,
alpha,
beta)
This function stores the resulting model in model_table. The table has only 1 row and is in the following form:
{TABLE} model_table (
voc_size INTEGER,
topic_num INTEGER,
alpha FLOAT,
beta FLOAT,
model BIGINT[])
This function also stores the topic counts and the topic assignments in each document in output_data_table. The table is in the following form:
{TABLE} output_data_table (
docid INTEGER,
wordcount INTEGER,
words INTEGER[],
counts INTEGER[],
topic_count INTEGER[],
topic_assignment INTEGER[])
The prediction (i.e. labelling of test documents using a learned LDA model) can be done with the following function:
SELECT lda_predict(
'data_table',
'model_table',
'output_table');
This function stores the prediction results in output_table. Each row in the table stores the topic distribution and the topic assignments for a docuemnt in the dataset. The table is in the following form:
{TABLE} output_table (
docid INTEGER,
wordcount INTEGER,
words INTEGER,
counts INTEGER,
topic_count INTEGER[],
topic_assignment INTEGER[])
SELECT lda_get_perplexity(
'model_table',
'output_data_table');
{TABLE} __internal_data_table__ (
docid INTEGER,
wordcount INTEGER,
words INTEGER[],
counts INTEGER[])
where docid is the document ID, wordcount is the number of words in the document, words is the list of unique words in the document, and counts is a list of the number of occurrences of each unique word in the document.
lda_train( data_table,
model_table,
output_data_table,
voc_size,
topic_num,
iter_num,
alpha,
beta
)
Arguments TEXT. The name of the table storing the training dataset. Each row is in the form <docid, wordid, count> where docid, wordid, and count are non-negative integers.
The docid column refers to the document ID, the wordid column is the word ID (the index of a word in the vocabulary), and count is the number of occurrences of the word in the document.
Please note that column names for docid, wordid, and count are currently fixed, so you must use these exact names in the data_table.
| voc_size | INTEGER. Size of the vocabulary. Note that the wordid should be continous integers starting from 0 to voc_size − 1. A data validation routine is called to validate the dataset. |
|---|---|
| topic_num | INTEGER. Number of topics. |
| alpha | DOUBLE PRECISION. Dirichlet parameter for the per-doc topic multinomial (e.g. 50/topic_num). |
| beta | DOUBLE PRECISION. Dirichlet parameter for the per-topic word multinomial (e.g. 0.01). |
| model | BIGINT[]. |
| docid | INTEGER. |
|---|---|
| wordcount | INTEGER. |
| words | INTEGER[]. |
| counts | INTEGER[]. |
| topic_count | INTEGER[]. |
| topic_assignment | INTEGER[]. |
wordid should be continous integers starting from 0 to voc_size − 1. A data validation routine is called to validate the dataset. Prediction—labelling test documents using a learned LDA model—is accomplished with the following function:
lda_predict( data_table,
model_table,
output_table
);
This function stores the prediction results in output_table. Each row in the table stores the topic distribution and the topic assignments for a document in the dataset. The table has the following columns:
| docid | INTEGER. |
|---|---|
| wordcount | INTEGER. |
| words | INTEGER[]. List of word IDs in this document. |
| counts | INTEGER[]. List of word counts in this document. |
| topic_count | INTEGER[]. Of length topic_num, list of topic counts in this document. |
| topic_assignment | INTEGER[]. Of length wordcount, list of topic index for each word. |
lda_get_perplexity( model_table,
output_data_table
);
DROP TABLE IF EXISTS documents; CREATE TABLE documents(docid INT4, contents TEXT); INSERT INTO documents VALUES (0, 'Statistical topic models are a class of Bayesian latent variable models, originally developed for analyzing the semantic content of large document corpora.'), (1, 'By the late 1960s, the balance between pitching and hitting had swung in favor of the pitchers. In 1968 Carl Yastrzemski won the American League batting title with an average of just .301, the lowest in history.'), (2, 'Machine learning is closely related to and often overlaps with computational statistics; a discipline that also specializes in prediction-making. It has strong ties to mathematical optimization, which deliver methods, theory and application domains to the field.'), (3, 'California''s diverse geography ranges from the Sierra Nevada in the east to the Pacific Coast in the west, from the Redwood–Douglas fir forests of the northwest, to the Mojave Desert areas in the southeast. The center of the state is dominated by the Central Valley, a major agricultural area. ');
term_frequency function (Term Frequency).
-- Convert a string to a list of words
ALTER TABLE documents ADD COLUMN words TEXT[];
UPDATE documents SET words = regexp_split_to_array(lower(contents), E'[\\s+\\.\\,]');
-- Create the term frequency table
DROP TABLE IF EXISTS my_training, my_training_vocabulary;
SELECT madlib.term_frequency('documents', 'docid', 'words', 'my_training', TRUE);
SELECT * FROM my_training order by docid limit 20;
docid | wordid | count
-------+--------+-------
0 | 57 | 1
0 | 86 | 1
0 | 4 | 1
0 | 55 | 1
0 | 69 | 2
0 | 81 | 1
0 | 30 | 1
0 | 33 | 1
0 | 36 | 1
0 | 43 | 1
0 | 25 | 1
0 | 65 | 2
0 | 72 | 1
0 | 9 | 1
0 | 0 | 2
0 | 29 | 1
0 | 18 | 1
0 | 12 | 1
0 | 96 | 1
0 | 91 | 1
(20 rows)
SELECT * FROM my_training_vocabulary order by wordid limit 20;
wordid | word
--------+--------------
0 |
1 | 1960s
2 | 1968
3 | 301
4 | a
5 | agricultural
6 | also
7 | american
8 | an
9 | analyzing
10 | and
11 | application
12 | are
13 | area
14 | areas
15 | average
16 | balance
17 | batting
18 | bayesian
19 | between
(20 rows)
lda_train() function.
DROP TABLE IF EXISTS my_model, my_outdata;
SELECT madlib.lda_train( 'my_training',
'my_model',
'my_outdata',
104,
5,
10,
5,
0.01
);
Reminder that column names for docid, wordid, and count are currently fixed, so you must use these exact names in the input table. After a successful run of the lda_train() function two tables are generated, one for storing the learned model and the other for storing the output data table.
-- The topic description by top-k words
DROP TABLE IF EXISTS my_topic_desc;
SELECT madlib.lda_get_topic_desc( 'my_model',
'my_training_vocabulary',
'my_topic_desc',
15);
select * from my_topic_desc order by topicid, prob DESC;
topicid | wordid | prob | word
---------+--------+--------------------+-------------------
1 | 69 | 0.181900726392252 | of
1 | 52 | 0.0608353510895884 | is
1 | 65 | 0.0608353510895884 | models
1 | 30 | 0.0305690072639225 | corpora
1 | 1 | 0.0305690072639225 | 1960s
1 | 57 | 0.0305690072639225 | latent
1 | 35 | 0.0305690072639225 | diverse
1 | 81 | 0.0305690072639225 | semantic
1 | 19 | 0.0305690072639225 | between
1 | 75 | 0.0305690072639225 | pitchers
1 | 43 | 0.0305690072639225 | for
1 | 6 | 0.0305690072639225 | also
1 | 40 | 0.0305690072639225 | favor
1 | 47 | 0.0305690072639225 | had
1 | 28 | 0.0305690072639225 | computational
....
-- The per-word topic counts (sorted by topic id)
DROP TABLE IF EXISTS my_word_topic_count;
SELECT madlib.lda_get_word_topic_count( 'my_model',
'my_word_topic_count');
SELECT * FROM my_word_topic_count ORDER BY wordid;
wordid | topic_count
--------+--------------
0 | {0,17,0,0,0}
1 | {1,0,0,0,0}
2 | {0,0,0,0,1}
3 | {0,0,0,0,1}
4 | {0,0,0,0,3}
5 | {0,1,0,0,0}
6 | {1,0,0,0,0}
7 | {1,0,0,0,0}
8 | {0,0,0,1,0}
9 | {1,0,0,0,0}
10 | {0,0,0,0,3}
11 | {0,0,1,0,0}
....
-- The per-document topic assignments and counts: SELECT docid, topic_assignment, topic_count FROM my_outdata;
docid | topic_assignment | topic_count
-------+-----------------------------------------------------------------------------------------------------------------+----------------
1 | {1,1,1,1,1,1,2,4,1,4,4,4,1,0,2,1,0,2,2,3,4,2,1,1,4,2,4,3,0,0,2,4,4,3,3,3,3,3,0,1,0,4} | {6,12,7,7,10}
3 | {1,1,1,1,1,1,4,0,2,3,1,2,0,0,0,1,2,2,1,3,3,2,2,1,2,2,2,0,3,0,4,1,0,0,1,4,3,2,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,4,3} | {8,12,10,21,4}
0 | {1,1,4,2,1,4,4,4,1,3,1,0,0,0,0,0,0,0,0,1,1,3,0,1} | {9,8,1,2,4}
2 | {1,1,1,1,4,1,4,4,2,0,2,4,1,1,4,1,2,0,1,3,1,2,4,3,2,4,4,3,1,2,0,3,3,1,4,3,3,3,2,1} | {3,13,7,8,9}
(4 rows)
SELECT madlib.lda_predict( 'my_testing',
'my_model',
'my_pred'
);
The test table (my_testing) is expected to be in the same form as the training table (my_training) and can be created with the same process. After a successful run of the lda_predict() function, the prediction results are generated and stored in my_pred. This table has the same schema as the my_outdata table generated by the lda_train() function.
SELECT madlib.lda_get_perplexity( 'my_model',
'my_pred'
);
[1] D.M. Blei, A.Y. Ng, M.I. Jordan, Latent Dirichlet Allocation, Journal of Machine Learning Research, vol. 3, pp. 993-1022, 2003.
[2] T. Griffiths and M. Steyvers, Finding scientific topics, PNAS, vol. 101, pp. 5228-5235, 2004.
[3] Y. Wang, H. Bai, M. Stanton, W-Y. Chen, and E.Y. Chang, lda: Parallel Dirichlet Allocation for Large-scale Applications, AAIM, 2009.
[4] http://en.wikipedia.org/wiki/Latent_Dirichlet_allocation
[5] J. Chang, Collapsed Gibbs sampling methods for topic models, R manual, 2010.
 1.8.13
1.8.13